大模型微调--几种AIGC的方法
随着团队方向慢慢转型向大模型方向,而大模型的训练往往不能像以前训练常规模型一样一个方向训练一个模型,由于其高昂的训练成本和时间成本,所以了解现在常用的大模型微调方法是有必要的,本次主要讲解LoRA:Low-Rank Adaptation of Large Language Models(ICLR2022 Microsoft团队)、DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation(CVPR 2023 Google)、Adding Conditional Control to Text-to-Image Diffusion Models(ICCV 2023 Best Paper 斯坦福大学)。
LoRA
如图所示 ,常见的几种微调方式是Full tuning、Adapters、Prompt Tuning等,Full tuning效果最好,因为是对其所有的模型参数进行了一次更新,缺点是训练时间过长。对于Adapters的方式来说,在模型中间添加额外的可训练层并冻结原来模型的参数,这样训练会引入额外的推理时间。对于Prompt Tuning来说,往往是取prompt的一段序列去影响原来的模型生成并冻结原来模型的参数,这影响了输入序列空间,影响模型的性能。
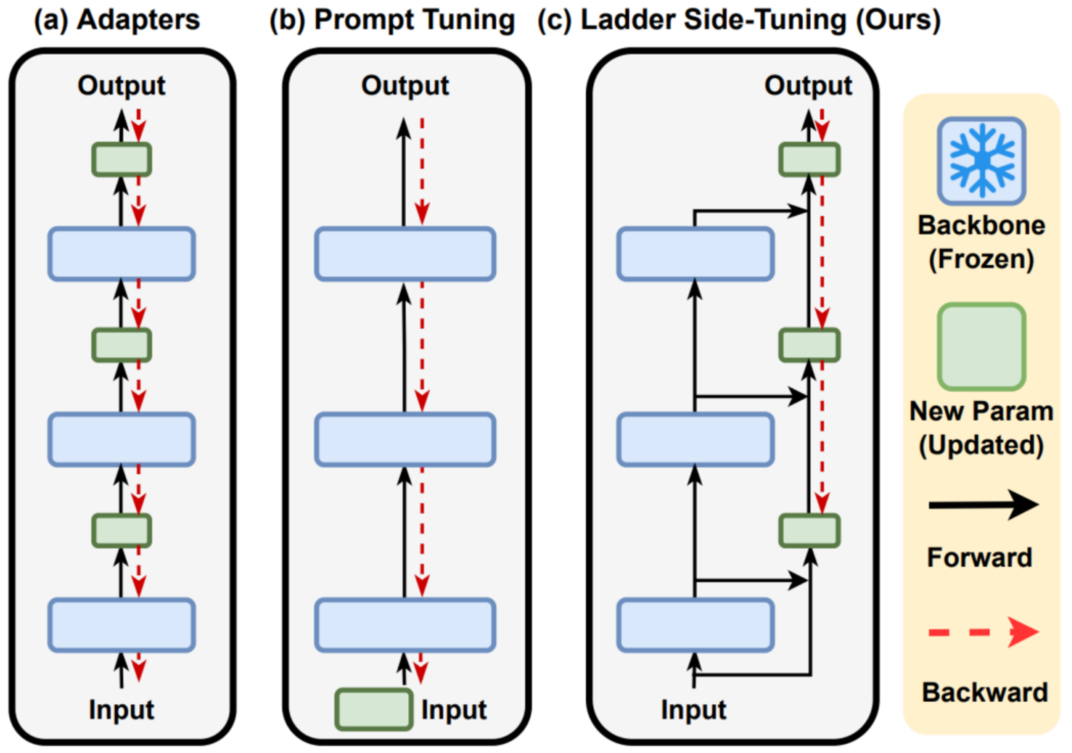
因为在模型训练好之后,再次微调模型,模型参数应该只会发生微小的变化。所以作者假设使用两个低矩阵秩去替代模型的参数,从而大大减小模型的参数量。
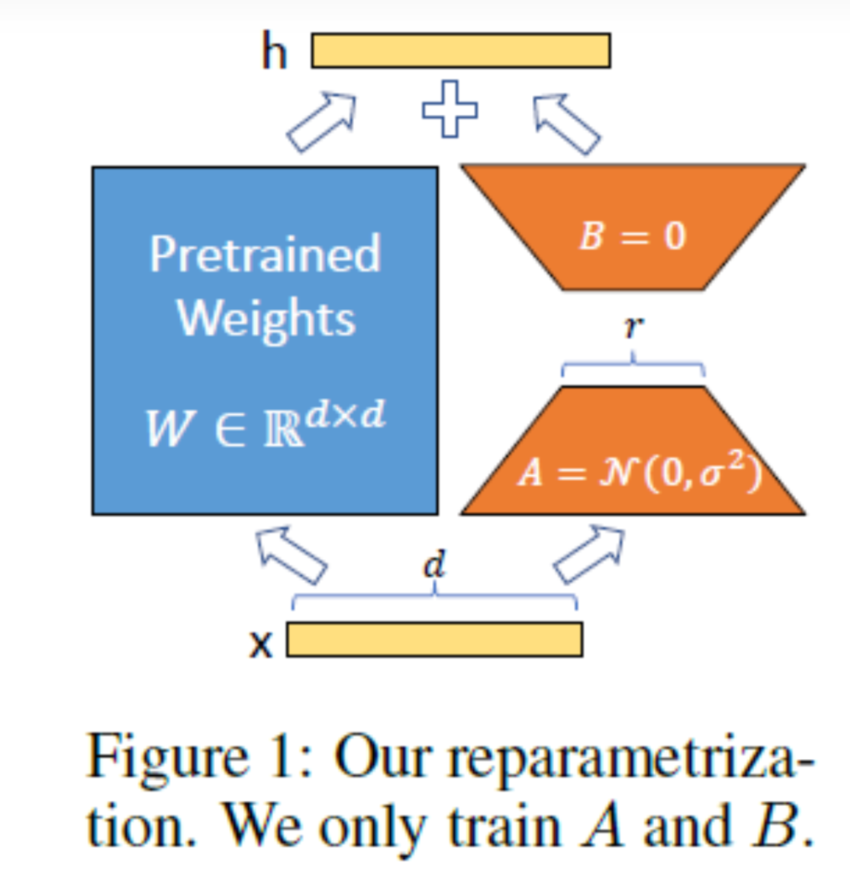

这样操作极大的减少了模型微调的参数量以及时间,目前被广泛用于Stable Diffusion Model 中, 来生成各式各样专用的图片。
DreamBooth
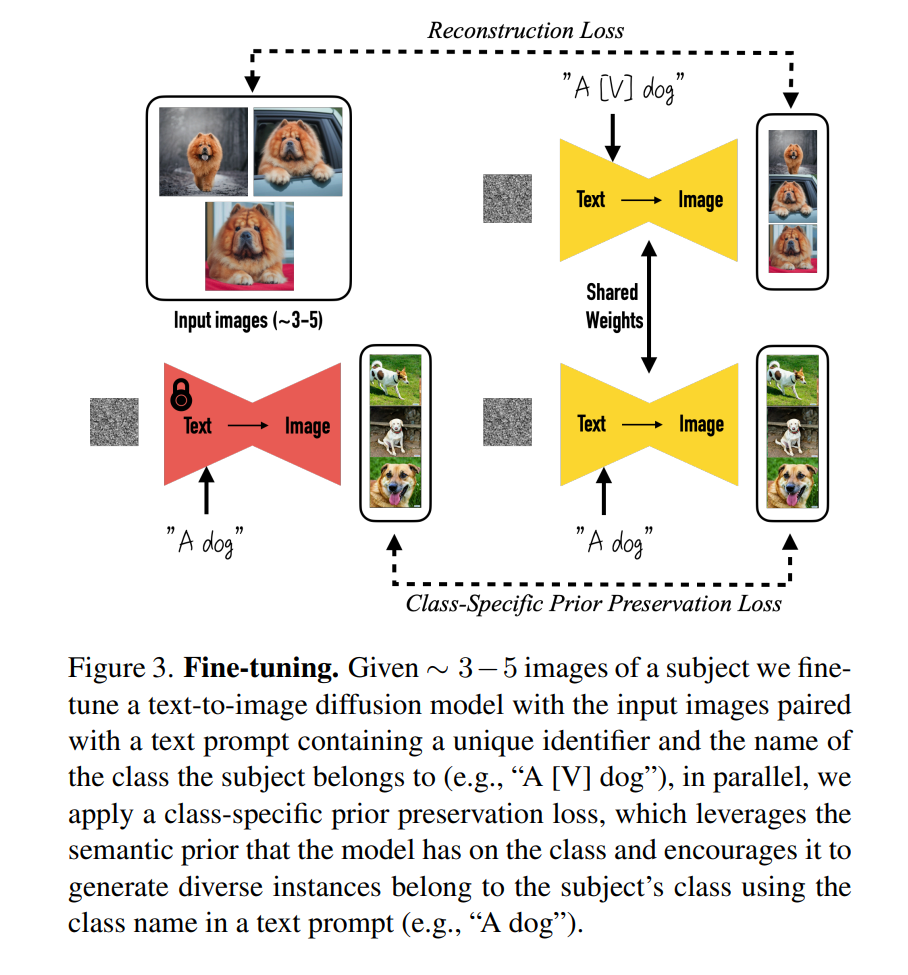
DreamBooth是一种Prompt微调方式,主要用于DIffusion Model中,使得扩散模型能够只使用几张图片便能记住给定图片的特征,将给定图片的主体内容生成出来并不破坏原有的模型生成能力。本文发现prompt模板使用“a [identifier] [class noun]”方式效果最好。identifier的选取方法是在词汇表中找到相对稀有的token,采样后映射成相应字符串。实验发现, 提取T5-XXL 分词器范围 {5000, ..., 10000} 中的token效果很好,使用随机抽样而不替换的方式,采样 3 个或更少的 Unicode 字符的对应的token组成identifier字符串。class noun选择要符合图像语义,效果最好。文中还指出单纯微调text-img的diffusion model可能会导致高频模糊,还需要微调超分网络。
其效果如下

ControlNet

ControlNet是使得diffusion model能够根据输入的控制信息去引导图像的生成。具体做法是将原来的扩散模型冻结,并复制一份参数,使用新的控制信息进行训练控制构图。
