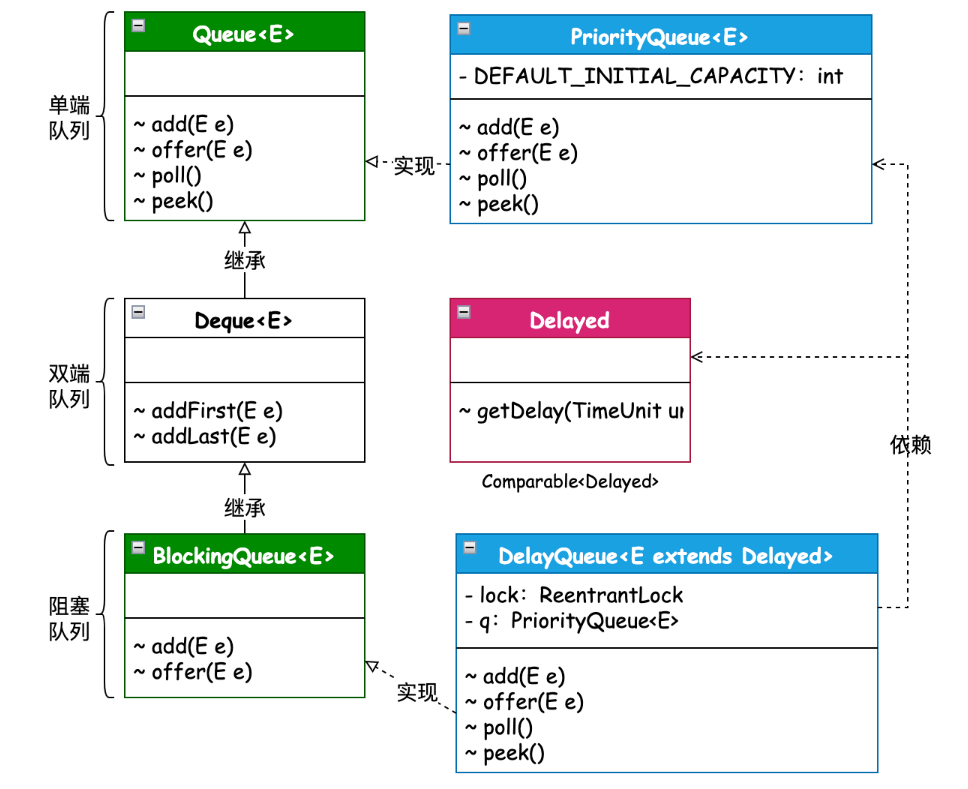
队列源码分析
1. 双端队列ArrayDeque
ArrayDeque 是基于数组实现的可动态扩容的双端队列。
1.1 初始化
和HashMap类似的方式, 容量一定是2的幂次方
private static int calculateSize(int numElements) {
int initialCapacity = MIN_INITIAL_CAPACITY;
// Find the best power of two to hold elements.
// Tests "<=" because arrays aren't kept full.
if (numElements >= initialCapacity) {
initialCapacity = numElements;
initialCapacity |= (initialCapacity >>> 1);
initialCapacity |= (initialCapacity >>> 2);
initialCapacity |= (initialCapacity >>> 4);
initialCapacity |= (initialCapacity >>> 8);
initialCapacity |= (initialCapacity >>> 16);
initialCapacity++;
if (initialCapacity < 0) // Too many elements, must back off
initialCapacity >>>= 1;// Good luck allocating 2 ^ 30 element
}
return initialCapacity;
}
1.2 数据插入
deque.push等于deque.offerFirst,两个源码如下
public void addFirst(E e) {
if (e == null)
throw new NullPointerException();
elements[head = (head - 1) & (elements.length - 1)] = e;
if (head == tail)
doubleCapacity();
}
public void addLast(E e) {
if (e == null)
throw new NullPointerException();
elements[tail] = e;
if ( (tail = (tail + 1) & (elements.length - 1)) == head)
doubleCapacity();
}
-
判断插入数据
-
插入
-
判断是否需要扩容
head是一个索引,表示队列的首元素(头部元素)所在的底层数组中的位置。tail是一个索引,表示队列的末尾位置 之后的一个空槽。
初始时 tail和head都为0,环形数组
1.3 数组扩容和数组迁移
及其是数组实现就避免不了扩容和数据迁移到新的位置
private void doubleCapacity() {
assert head == tail;
int p = head;
int n = elements.length;
int r = n - p; // number of elements to the right of p
int newCapacity = n << 1;
if (newCapacity < 0)
throw new IllegalStateException("Sorry, deque too big");
Object[] a = new Object[newCapacity];
System.arraycopy(elements, p, a, 0, r);
System.arraycopy(elements, 0, a, r, p);
elements = a;
head = 0;
tail = n;
}
/*
src:源数组(需要复制的数组)。
srcPos:源数组的起始位置(从哪里开始复制,索引从 0 开始)。
dest:目标数组(复制的目标数组)。
destPos:目标数组的起始位置(目标数组的起始索引位置,将源数组元素复制到目标数组的哪个位置)。
length:要复制的元素个数
*/
public static void arraycopy(Object src, int srcPos, Object dest, int destPos, int length)
2. 双端队列LinkedList
链表实现,从头尾取数据时间复杂度O(1), 同时数据的插入和删除也不需要像数组队列那样拷贝数据。
2.1 头插入
deque.push("a") 、 deque.offerFirst("a")
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
2.2 尾插入
deque.offerLast("e");
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
3 优先队列PriorityQueue
优先队列本质是一个数组构成的二叉堆
二叉堆
- 假如父节点为queue[n],那么左子节点为queue[2n+1],右子节点为queue[2n+2]
- 任意孩子节点的父节点位置,都是
(n-1)>>>1相当于减1后除2取整 - 父节点小于等于任意孩子节点
- 同一层级的两个孩子节点大小不需要维护,它是在弹出元素的时候进行判断的
- 一个长度为 size 的优先级队列,当 index >= size >>> 1 时,该节点为叶子节点。否则,为非叶子节点。
3.1 扩容机制
private void grow(int minCapacity) {
int oldCapacity = queue.length;
// Double size if small; else grow by 50%
int newCapacity = oldCapacity + ((oldCapacity < 64) ?
(oldCapacity + 2) :
(oldCapacity >> 1));
// overflow-conscious code
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
queue = Arrays.copyOf(queue, newCapacity);
}
- 如果数组长度小于64:每次增加2
- 如果数组长度大于64:每次翻倍
- 如果超过整数上限则设置为上限
3.2 元素入队
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length)
grow(i + 1);
siftUp(i, e);
size = i + 1;
return true;
}
// siftUp会使用Cimparator进行元素比较,如果没有指定具体Comparator,就采用元素对应的Comparator
private void siftUpUsingComparator(int k, E x) {
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (comparator.compare(x, (E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = x;
}
3.3 元素出队
public E poll() {
final Object[] es;
final E result;
if ((result = (E) ((es = queue)[0])) != null) {
modCount++;
final int n;
final E x = (E) es[(n = --size)];
es[n] = null;
if (n > 0) {
final Comparator<? super E> cmp;
if ((cmp = comparator) == null)
siftDownComparable(0, x, es, n);
else
siftDownUsingComparator(0, x, es, n, cmp);
}
}
return result;
}
private static <T> void siftDownUsingComparator(
int k, T x, Object[] es, int n, Comparator<? super T> cmp) {
// assert n > 0;
int half = n >>> 1;
while (k < half) {
int child = (k << 1) + 1;
Object c = es[child];
int right = child + 1;
if (right < n && cmp.compare((T) c, (T) es[right]) > 0)
c = es[child = right];
if (cmp.compare(x, (T) c) <= 0)
break;
es[k] = c;
k = child;
}
es[k] = x;
}
将数组元素从根节点,放到叶子节点,然后删掉。
4. 延时队列DelayQueue
DelayQueue 是阻塞队列实现的,扩充了PriorityQueue和ReentrantLock锁。
4.1 元素入队
delayQueue.offer(new TestDelayed("aaa", 5, TimeUnit.SECONDS));
public boolean offer(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
q.offer(e);
if (q.peek() == e) {
available.signal();
}
return true;
} finally {
lock.unlock();
}
}
4.2 元素出队
最小化的空等时间,提高线程利用率。有锁
public E poll() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
E first = q.peek();
return (first == null || first.getDelay(NANOSECONDS) > 0)
? null
: q.poll();
} finally {
lock.unlock();
}
}
4.3 元素消费
private final Condition available = lock.newCondition();
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
E first = q.peek();
if (first == null)
available.await();
else {
long delay = first.getDelay(NANOSECONDS);
if (delay <= 0L)
return q.poll();
first = null; // don't retain ref while waiting
if (leader != null)
available.await();
else {
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
available.awaitNanos(delay);
} finally {
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
if (leader == null && q.peek() != null)
available.signal();
lock.unlock();
}
}
-
DelayQueue使用 leader/follower 模式来优化线程唤醒。 当一个线程发现队列头部的元素还未到期时,它就成为 leader,负责等待剩余的时间。 其他线程到达时,如果发现已经有 leader,就直接进入等待状态,而不用竞争 leader 的身份。 这样可以减少不必要的唤醒和上下文切换,提高性能。 -
available: available是Condition,比
wait()/notify()机制更细粒度的线程控制,Condition允许你创建多个等待集合
常见面试问题
单端队列和双端队列,分别对应的实现类是哪个?
-
单端队列 (Queue):
LinkedList:LinkedList实现了Queue接口,可以用作单端队列。 它基于链表,提供了先进先出 (FIFO) 的特性。PriorityQueue: 优先级队列,但也可以理解为一种特殊的单端队列,只不过出队顺序是按照元素的优先级来的。 -
双端队列 (Deque):
LinkedList:LinkedList也实现了Deque接口,因此它也可以作为双端队列使用。 这意味着你可以在队列的两端进行插入和删除操作。ArrayDeque: 基于动态数组实现的双端队列,性能比LinkedList好,特别是在随机访问方面。
简述延迟队列/优先队列的实现方式?
-
延迟队列: 实现了优先队列,并进行扩充
-
基于优先队列 + 时间戳:
最常见的实现方式。
- 使用
PriorityQueue来存储元素。 - 每个元素都关联一个 "到期时间" (时间戳)。
PriorityQueue按照到期时间排序,到期时间最早的元素排在队首。- 从队列中取出元素前,检查队首元素的到期时间是否已过。如果未过,则阻塞(例如,通过
Thread.sleep()或LockSupport.parkNanos())等待一段时间再检查。 可以使用一个专门的线程来做这个检查和等待。
- 使用
-
基于时间轮: 适合高并发场景。 将时间划分成多个槽位,每个槽位对应一个时间段。 将延迟任务放入对应的槽位中,然后一个时间轮指针按固定间隔移动,当指针指向一个槽位时,就处理该槽位中的任务。
-
-
优先队列:
- 二叉堆: 最常见的实现方式。 Java 中的
PriorityQueue默认就是使用二叉堆实现的。
- 二叉堆: 最常见的实现方式。 Java 中的
二叉堆插入/弹出元素的过程?
-
插入元素 (Insert):
-
添加到堆的末尾: 将新元素添加到堆的最后一个位置(数组的最后一个元素)。
-
上浮 (Heapify Up / Bubble Up):
将新元素与其父节点进行比较。
- 如果新元素比父节点更“优先”(对于最小堆,这意味着新元素更小;对于最大堆,这意味着新元素更大),则交换它们的位置。
- 重复这个比较和交换的过程,直到新元素到达根节点,或者它的优先级不再高于其父节点。
-
-
弹出元素 (Extract Min/Max):
-
取出根节点: 将根节点(最小堆中的最小值或最大堆中的最大值)取出。
-
用最后一个元素替换根节点: 将堆的最后一个元素移动到根节点的位置。
-
下沉 (Heapify Down / Sink Down):将新的根节点与其子节点进行比较。
-
如果新的根节点比它的一个或多个子节点优先级更低(对于最小堆,这意味着新的根节点更大;对于最大堆,这意味着新的根节点更小),则选择优先级最高的子节点(对于最小堆,选择最小的子节点;对于最大堆,选择最大的子节点),并交换它们的位置。
-
重复这个比较和交换的过程,直到新的根节点到达叶子节点,或者它的优先级不再低于其任何子节点。
-
-
延迟队列的使用场景?
- 取消订单: 用户下单后,一段时间内未支付,自动取消订单。
- 缓存过期: 缓存项在一段时间后自动过期。
- 定时任务: 在指定时间执行某个任务(虽然通常有更专业的定时任务调度框架,但延迟队列可以作为一种轻量级的替代方案)。
- 重试机制: 在某个操作失败后,延迟一段时间后重试。
- 会话管理: 在用户长时间不活动后,使会话过期。
- 通知推送: 在特定时间点向用户发送通知。
延迟队列为什么添加信号量?(JAVA使用的是Condition)
在某些延迟队列的实现中,特别是那些需要阻塞等待元素到期的实现中,信号量(Semaphore)可以用来优化性能和避免不必要的 CPU 消耗。 以下是使用信号量的原因:
- 避免忙等待 (Busy-Waiting): 如果使用简单的
while循环来检查队首元素是否到期,会导致 CPU 持续运行,即使队列中没有到期的元素。 这被称为忙等待,效率很低。 - 线程唤醒: 当有新的元素添加到延迟队列中,并且该元素的到期时间比当前队首元素的到期时间更早时,需要唤醒正在等待的线程,以便它能够重新检查队首元素
信号量的工作方式:
- 初始化信号量: 信号量初始化为 0。
- 等待: 当线程从延迟队列中取元素时,如果队首元素未到期,线程会调用
semaphore.acquire()方法来阻塞自己。acquire()方法会阻塞线程,直到信号量的值大于 0。 - 添加元素和释放信号量: 当向延迟队列中添加新元素时,如果新元素的到期时间比当前队首元素的到期时间更早,会调用
semaphore.release()方法来释放信号量。release()方法会将信号量的值增加 1,从而唤醒一个正在等待的线程。