粒矩聚类图像矩阵多线程加速
第一次组会:导师安排的任务,使用多线程对图片处理进行加速。
多线程分析
在粒矩聚类算法中,图像矩阵img_label是一个用于标记像素点归属的矩阵,初始化时,所有像素点的归属都是未知的,可以将其全部设置为0,然后在聚类过程中,每个粒矩所包含的像素点都会被标记为1,表示这些像素点已经被聚类到某个粒矩内。因此,在多线程版本中,我们需要将img_label矩阵按行分割成num_threads份,然后分别处理。这样做能够同时处理多个子矩阵,提高聚类速度,而且每个子矩阵内部的像素点是连续的,不会导致像素点的漏标或重标问题。
原始代码
start = time.time()
while 0 in img_label: # 存在没有被划分的点
# 选择一个梯度最小且没有被划分过的点为中心点
temp_center = center_select(img_grad, img_label)
# 计算半径 Rx, Ry -> x 方向的半径与 y 方向的半径
Rx, Ry = cal_Radius(img, temp_center, purity, threshold, var_threshold)
# 计算实际的矩形在图片中的位置(存在粒矩大小超出图像范围,所以不能直接用半径进行切片),方便后续使用切片进行特征提取等操作
left, right, up, down = cal_bound(img, temp_center, Rx, Ry)
# 添加粒矩 ([x, y], Rx, Ry) 一个粒矩一个元组.最基础特征:中心点坐标, Rx, Ry
center.append((temp_center, Rx, Ry)) # 粒矩存储方式待优化
# 将本次迭代生成的粒矩包含的像素点标记 (下次迭代就不会选取这些点作为中心点)
img_label[up:down + 1, left:right + 1] = 1
# 将本次迭代生成的粒矩包含的像素点对应位置的梯度设为梯度最大值
img_grad[up:down + 1, left:right + 1] = max_Grad
# 粒矩计数
center_count += 1
end = time.time()
print("粒矩聚类时间:%.2f秒" % (end - start))
print("共生成" + str(center_count) + "个粒矩")`
多线程代码
def multi(img_label):
global center_count
global center
global img
global img_grad
global purity
global threshold
global var_threshold
while 0 in img_label:
temp_center = center_select(img_grad, img_label)
# 计算半径 Rx, Ry -> x 方向的半径与 y 方向的半径
Rx, Ry = cal_Radius(img, temp_center, purity, threshold, var_threshold)
# 计算实际的矩形在图片中的位置(存在粒矩大小超出图像范围,所以不能直接用半径进行切片),方便后续使用切片进行特征提取等操作
left, right, up, down = cal_bound(img, temp_center, Rx, Ry)
# 添加粒矩 ([x, y], Rx, Ry) 一个粒矩一个元组.最基础特征:中心点坐标, Rx, Ry
center.append((temp_center, Rx, Ry)) # 粒矩存储方式待优化
# 将本次迭代生成的粒矩包含的像素点标记 (下次迭代就不会选取这些点作为中心点)
img_label[up:down + 1, left:right + 1] = 1
# 将本次迭代生成的粒矩包含的像素点对应位置的梯度设为梯度最大值
img_grad[up:down + 1, left:right + 1] = max_Grad
# 粒矩计数
center_count += 1
def xx(img_label,num_threads=8):
chunk_size=img_label.shape[0]
threads = []
for i in range(num_threads):
start = i * chunk_size
end = start + chunk_size if i != (num_threads - 1) else None
img_label_chunk = img_label[start:end]
# img_label1, img_label2, img_label3, img_label4= np.array_split(img_label,4)
thread = threading.Thread(target=multi, args=(img_label_chunk,))
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
if __name__ == '__main__':
start = time.time()
xx(img_label)
end = time.time()
print("粒矩聚类时间:%.2f秒" % (end - start))
print("共生成" + str(center_count) + "个粒矩")
效果
多线程加速之后的用时:

不使用多线程加速的用时:
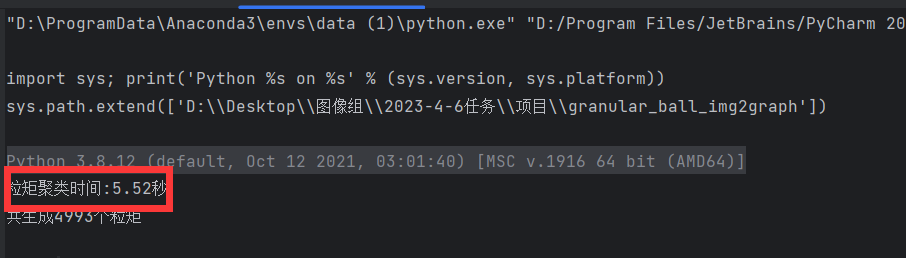
结论
使用多线程同时处理多个矩阵,能够提高聚类速度,而且每个子矩阵内部的像素点是连续的,不会导致像素点的漏标或重标问题。